
清华团队最新芯片报告:原创框架性能提4.8倍,入选顶会ISCA2020
对于许多数据密集型的应用分析而言,高效求解的大规模图计算算法是至关重要的。因此,人们提出了大量的图分析框架来对多种图计算算法进行性能优化,其应用从CPU拓展到GPU、FPGA和ASIC。
然而,多样性的计算平台也给图分析带来了异质性,大量的协调和同步工作使得图分析框架很难从单一平台扩展到异构平台。
此外,现有框架在优化迭代算法时仅关注单次迭代的执行时间,很少对算法收敛所需迭代次数进行探讨,因此,算法性能的整体优化遇到了显著瓶颈。
从工作方法上说,以往的工作大多依靠经验实现优化收敛速度,缺乏系统的收敛速度分析和优化方法来迭代图算法。
这些瓶颈若不能突破,必将严重制约图计算框架的完善,也会极大限制大数据分析等领域的进一步发展。
撰文 | 徐丹、吴昕
上周,第47届国际计算机体系结构大会(ISCA)通过线上形式进行。清华大学魏少军、刘雷波教授团队发表了题为《GraphABCD:通过分块坐标下降扩展图分析》(GraphABCD: Scaling Out Graph Analytics with Asynchronous Block Coordinate Descent )的学术报告。

该报告介绍了一种在可重构架构下(FPGA平台)将图计算问题转化为最优化问题,利用 分块坐标下降(Block Coordinate Descent ,简称BCD) 执行模型,可以同时优化图计算算法的迭代次数和单次迭代时间。
该方法充分利用了可重构阵列的空间并行性,给出了一个优化图计算框架性能的全新视角,相比传统方法具有显著优势。
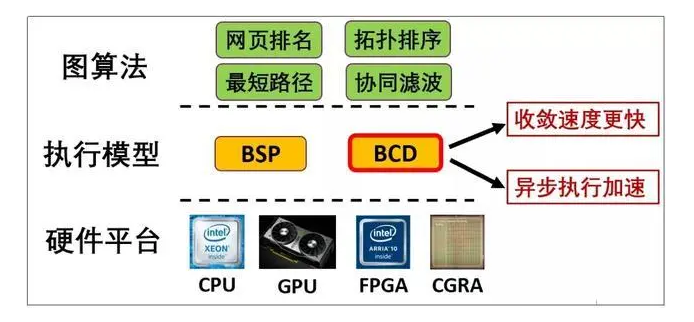
实验结果表明,在单源最短路径、PageRank、协同滤波等重要图算法上,新型计算框架GraphABCD 相比现行主流图计算框架GraphMat,收敛速度提高了4.8倍,执行时间提升了2倍。
论文主要由清华大学魏少军、刘雷波团队完成,在过去十余年中,他们在动态可重构芯片领域取得了多项重要技术突破,关键技术在多项国家重大工程中得到批量应用。
论文第一作者杨轶凡目前正在麻省理工学院攻读博士学位。这篇文章是他在清华攻读学士学位时完成的。论文通讯作者是刘雷波教授,主要合作者还有李兆石、刘志伟、尹首一、邓仰东等。
一 可重构芯片的想象力
该篇论文的核心就是提出了面向可重构芯片的图计算加速技术。
可重构芯片是一种软硬件可编程的芯片,相比于普通芯片,可重构芯片有诸多卓越性,包括软硬件可编程、硬件架构的动态可变性及高效的架构变换能力、兼具高计算效率和高能量效率、不需要芯片设计能力的应用简便性和软件定义芯片能力等。
可重构芯片一个明显的优势是可复用性。半导体制程的演进带来了高成本问题。仅研发一款14nm制程的芯片综合成本高达1.5-2亿美元,销售3000万颗以上才能把研发成本摊销到每颗芯片上。
这时复用芯片就会成为一个不错的选择。相同的芯片,功能可通过软件改变,不同的软件写入就变成了「专用」芯片。目前,国内大多AI芯片的设计思路正是基于此。

魏少军教授被选为2020年度IEEE产业先驱奖(Industry Pioneer Award)获奖人,图片来源清华大学微电子所。
论文的主要作者,魏少军、刘雷波团队是国内可重构芯片的领军人物。魏少军是清华大学微纳电子学系主任、微电子学研究所所长,曾带领团队登上世界顶级高性能芯片顶级会议Hot Chips,先后获得国家知识产权局和世界知识产权组织中国专利金奖、国际半导体产业协会(SEMI)突出贡献奖、第五届世界互联网大会全球领先科技成果等,并在2019年当选IEEE会士。
二 将图计算问题转化为最优化问题
针对图计算技术瓶颈,魏少军团队的研究集中成果在两个方面。
首先是将图计算问题转化为最优化问题,将最优化分析的分块坐标下降方法(Block Coordinate Descent ,简称BCD)创新性地引入到图计算框架中。
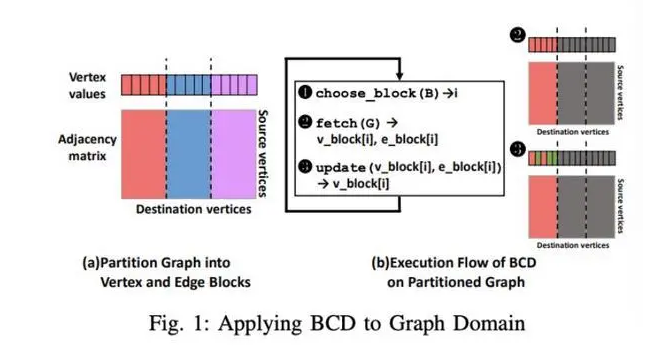
图1:将分块坐标下降算法应用于图形域模型
现有图计算框架局限性的症结在于,采用整体同步并行执行模型,即图计算每次迭代都利用屏障进行全局同步。整体同步并行模型不仅限制了框架的可扩展性,而且无法在算法执行过程中动态优化算法收敛所需的迭代次数。
在分块坐标下降方法执行模型下,图算法的迭代过程不再依赖全局同步,而是在每次迭代中选择一个或多个由子图构成的数据块,按照坐标下降的方法进行更新,直至算法收敛。
该研究通过分析数据块的大小、选择顺序和更新方法这三个变量来辨别块坐标下降模型参数对收敛速度的影响,能够系统地优化算法收敛所需迭代次数。
实验结果证明,更大的块大小意味着更慢的收敛,但有更明确的并行性和位置记忆,适合解决冲突或随机内存访问中开销较大的系统。
优先级调度由于包含了高阶全局信息,收敛速度更快。然而,该方案需要更多的工人之间的全局协调来提取信息,这可能会在高度异构的分布式系统中造成严重的延迟。
同时,由于多个数据块之间无须同步,块坐标下降可实现异步并发执行。
三 原创GraphABCD框架
研究的第二个成果是根据块坐标下降视图方法设计并实现了GraphABCD框架异构系统。
系统中包含一个CPU和硬件加速器,通过减少迭代次数大大提高迭代图算法点收敛速度,可以以异步执行的方式扩展到可重构芯片上。
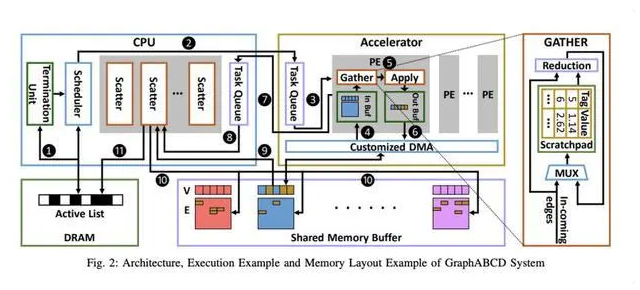
图2:GraphABCD系统的架构、执行示例和内存布局示例
GraphABCD框架异构系统包括如下个关键设计:
实现快速收敛。GraphABCD的目标是在异构平台上同步实现轻量级的快速收敛,所以它同时支持优先级调度和简单循环块选择方法。支持优先级块选择方法是由于其快速收敛点特性,然而运行时较大的开销可能会抵消改进的收敛速度,因此也支持简单循环块选择方法。
实现更好的内存位置和宽带利用率。图计算算法的不规则性很大程度上来自于大量的数据随机访问。GraphABCD选择「pull-push」作为顶点操作符和边缘图格式,结合在异构系统上的任务分配,能够确保所有的加速器内存访问都是有顺序的。
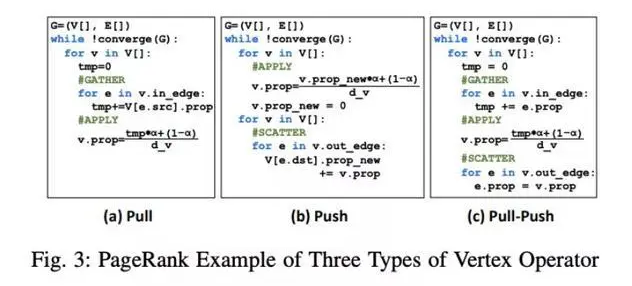
图3:三种类型的顶点运算符的PageRank示例
支持异步执行。如果部署同步执行模型,系统中异构组建之间的高同步开销会严重降低性能。在异步BCD保证了异步收敛性的情况下,GraphABCD通过,基于状态更新信息、解耦的CPU加速执行和不连续的块内存布局实现了以最小的协调开销设计异步执行。
CPU-FPGA混合执行优化。GraphABCD会将计算分配给加速器和可用的CPU,以有效地利用异构系统。为此,团队构造了一个CPU版本的收集-应用函数,并在运行时检测到CPU充分利用它。
最后,团队在FPGA上实现了硬件加速器的原型,并将整个GraphABCD系统部署在现有的CPU-FPGA异构系统Intel HARPv2 CPU-FPGA系统上,证实了该框架的可用性。
在GraphABCD中,简单的定制硬件模块(GATHER, APPLY)和软件功能(SCATTER)作为API暴露给最终用户。这些模块和功能可以修改,使框架适应不同算法。硬件方面,GraphABCD为定制逻辑提供了一个直接的数据流接口。定制组件可以由高级合成工具或通过集成现有ip生成。
实验结果环节,团队将GraphABCD与三种迭代图算法,PageRank (PR)、单源最短路径(SSSP)和协同过滤(CF)在7个真实图上(以edgelist格式)运行。每一种算法运行到收敛9次,并报告执行时间。
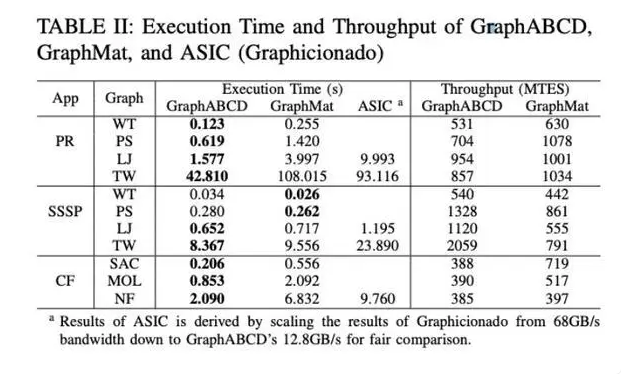
图4:GraphABCD、GraphMat和ASIC (Graphicionado)的执行时间和吞吐量
实验结果表明,在单源最短路径、PageRank、协同滤波等重要图算法上,新型计算框架GraphABCD 相比现行主流图计算框架GraphMat,收敛速度提高了4.8倍,执行时间提升了2倍。
 苏公网安备 32080402000117号
苏公网安备 32080402000117号
